

【新智元导读】老黄GTC重点展示的PD分离技术为何成兵家必争之地?UCSD全华人团队力作,创新性地提出预填充-解码分离技术。在严格的延迟约束下,相比现有最先进的服务系统,可实现高达4.48倍的有效产出率或10.2倍更严格的SLO达成率。
现在,PD分离已经成为兵家必争之地。
前有Mooncake/DeepSeek等公司采用这种技术来优化大模型的推理服务,后有Nvidia/PyTorch基于该技术孵化下一代LLM服务系统。
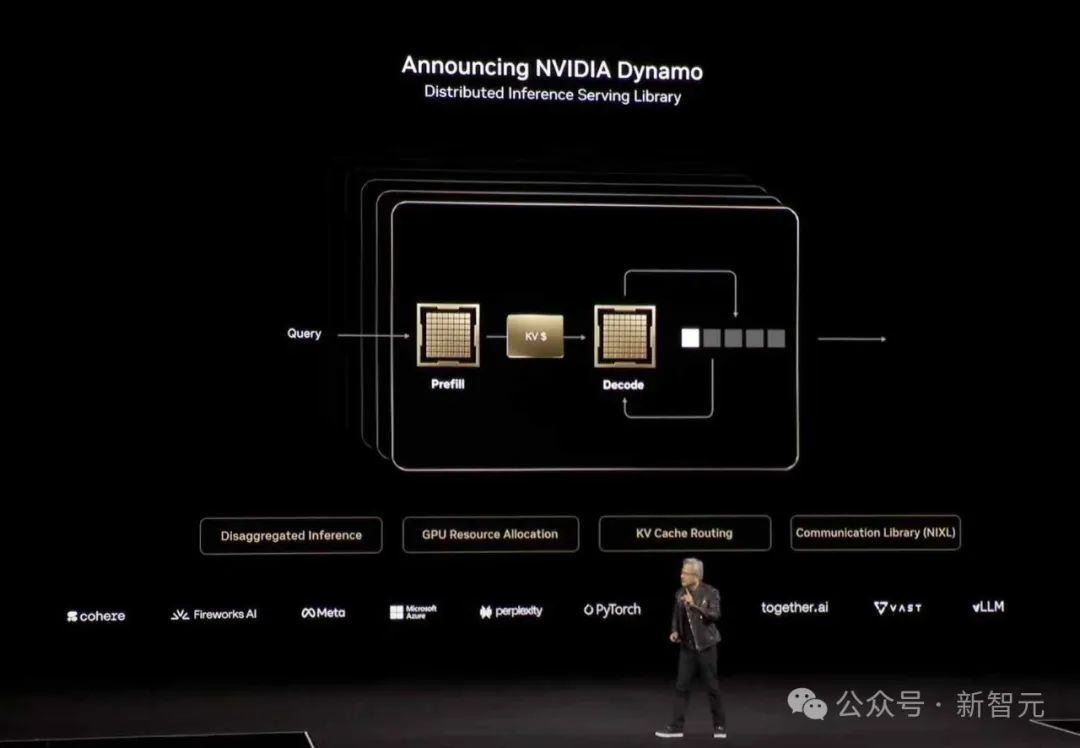
甚至最近,黄仁勋也在2025 GTC的舞台上提到了PD分离(Prefill-Decode Disaggregation)技术,进一步证明了这一技术获得的广泛关注。
去年,来自UCSD的一个华人团队发布的一篇博客,就深入剖析了这一技术的原理和它的应用场景。

如今,大语言模型应用有着不同的延迟需求。
例如,聊天机器人需要快速响应(比如低于0.2秒),而解码速度可以较为适中,仅需与人类阅读速度相匹配;代码补全则要求快速生成,以便实时提供代码建议。
文章中展示了现有的优化吞吐量的服务系统,在延迟标准下并不理想。
作者提议使用「有效吞吐量」(goodput)作为大模型服务性能的改进衡量标准,它不仅关注每秒完成请求的数量,而且符合服务级目标(SLO),更好地平衡成本和用户体验。
为了提升有效吞吐量,文章提出了「预填充-解码分离」(prefill-decode disaggregation),即将预填充和解码分配到不同的GPU上。
通过这个方法,作者搭建了一个系统原型DistServe,在保持严格的延迟约束下,达到了比现有系统高出4.48倍的有效吞吐量,或者10.2倍更严格的SLO。
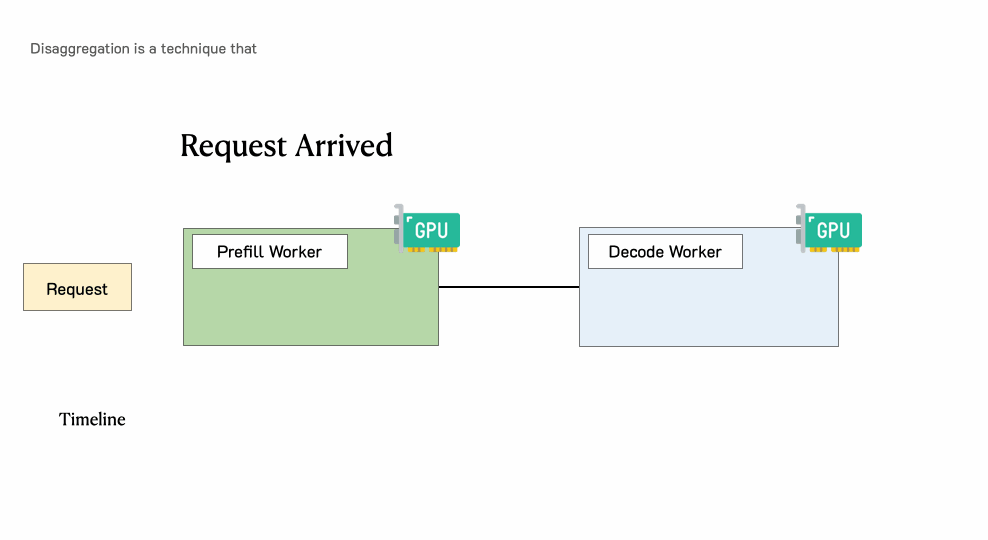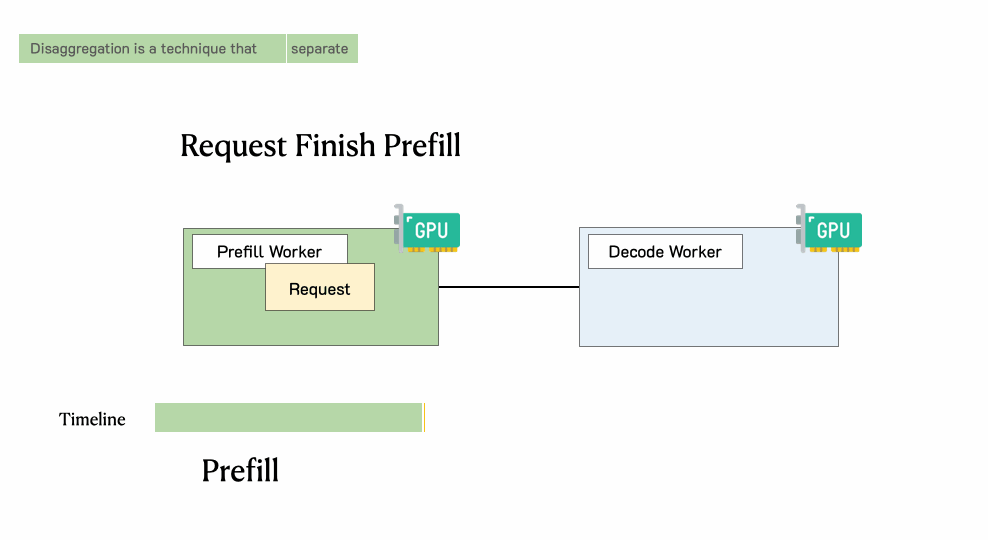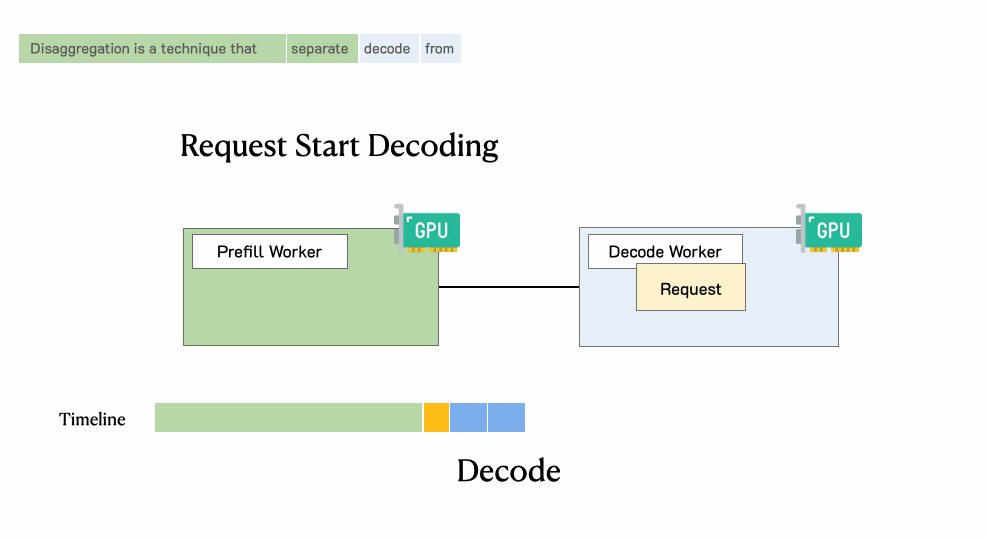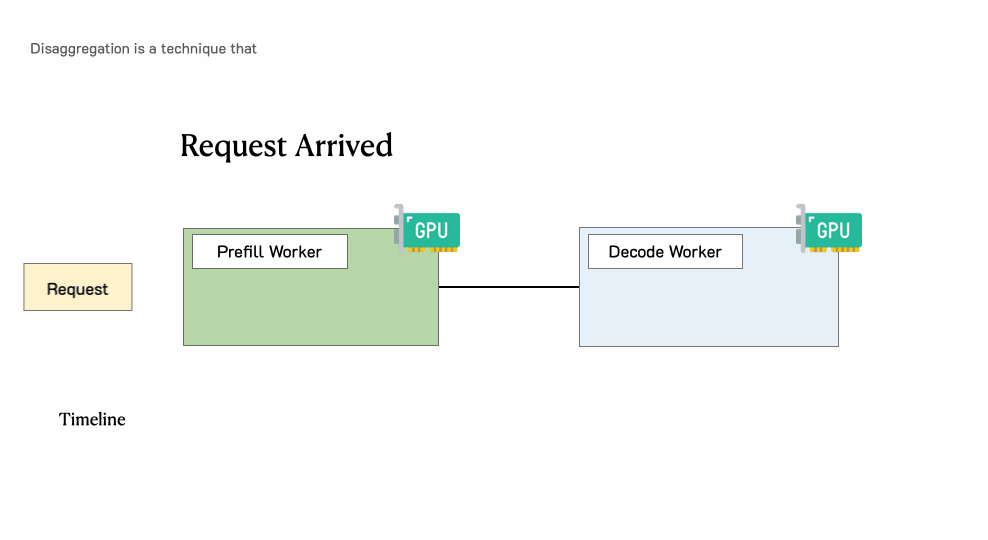
一个请求通过一个具有分离预填充和解码的LLM服务引擎
吞吐量与有效吞吐量
LLM正在改变行业对AI的应用,但LLM服务成本仍然很高。
为了降低成本,很多公司专注于提升LLM系统的吞吐量,即每秒处理的请求数(rps),作为每个请求成本($/req)的替代指标。
大多数流行的LLM服务引擎,如vLLM和TensorRT-LLM,都用吞吐量来衡量性能。
然而,实际应用对延迟的要求各不相同,因此服务级目标(SLO)也不同。常见的SLO包括:
首次token延迟(TTFT):测量LLM生成第一个token的时间
每个输出token的时间(TPOT):测量两个连续生成的token之间的平均延迟
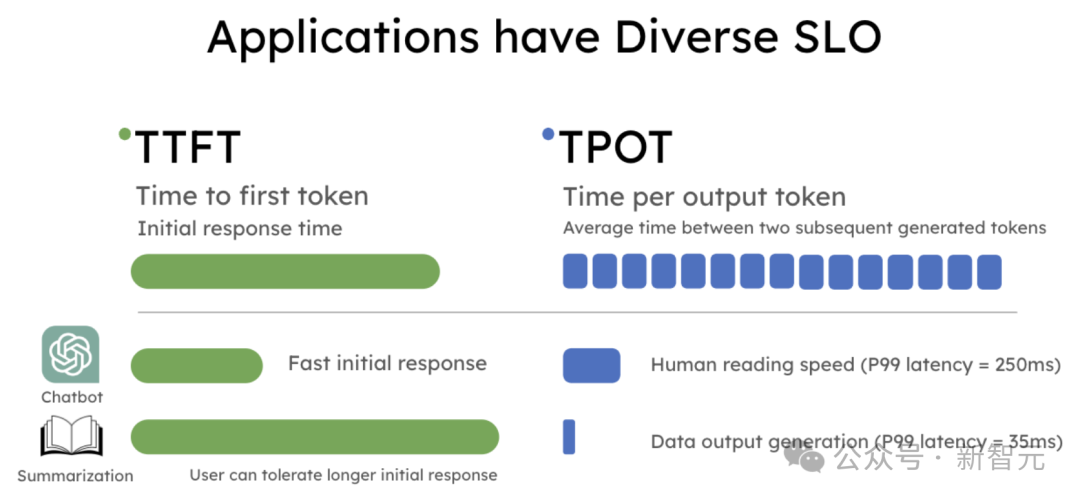
应用程序有着多样的SLO要求
吞吐量只关注处理的请求或token数,却忽视了这些延迟需求。作者引入了有效吞吐量(goodput),它衡量每秒完成的符合SLO的请求数(同时满足TTFT和TPOT要求)。这比吞吐量更能反映服务质量,因为它考虑了成本和用户体验。
那么,到底什么是有效吞吐量?假设一个应用要求90%的请求TTFT小于200毫秒,TPOT小于50毫秒,那么有效吞吐量就是每秒能完成的最大请求数,且至少90%的请求同时满足这两个条件。
一个高吞吐量的应用可能有低的有效吞吐量。虽然吞吐量是10个请求每秒,但因为延迟约束,只有3个请求符合SLO,最终的有效吞吐量只有每秒3个请求。可以想象,尽管这种系统的吞吐量很高,但它的用户服务将很差。
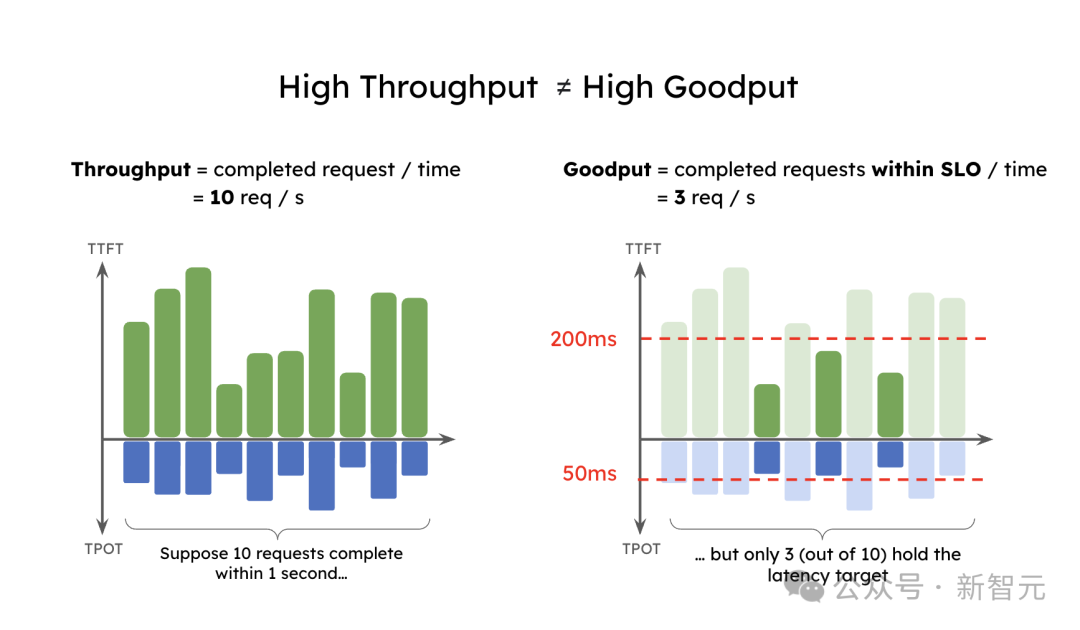
高吞吐量≠高有效吞吐量
以下是在本小节中引入的术语:
有效吞吐量:衡量LLM服务系统效能的指标,考虑了成本和用户满意度。它定义为每秒系统可以完成的请求数量,同时满足指定的服务级目标(SLO)。
吞吐量:LLM服务系统每秒处理的已完成请求数量。
服务级目标(SLO):LLM服务系统必须满足的目标,以提供令人满意的用户体验。常见的SLO包括首次token延迟(TTFT)、每个输出token时间(TPOT)、端到端延迟(E2E)和指数加权平均(EMA)延迟。
预填充:LLM推理的第一阶段,处理所有输入token,填充KV缓存,并生成第一个输出token。
解码:随后的阶段,通过自回归方式生成token,直到完成。
首次token延迟(TTFT):LLM服务系统响应用户请求时,生成第一个token所需的时间。
每个输出token的时间(TPOT):LLM服务系统响应用户请求时,生成后续token所需的平均时间。
为什么现有系统无法实现高有效吞吐量?
在深入分析之前,需要回顾一下LLM服务请求的流程。下图展示了这个过程:请求进入LLM推理引擎,系统首先处理用户输入生成的第一个token(预填充),然后通过自回归生成后续token(解码)。一个请求通常包括一个预填充步骤和多个解码步骤,直到生成完成。
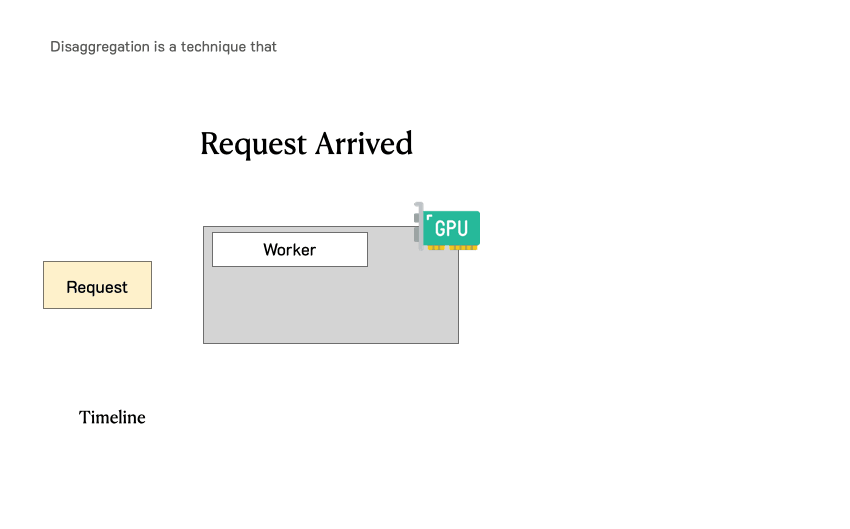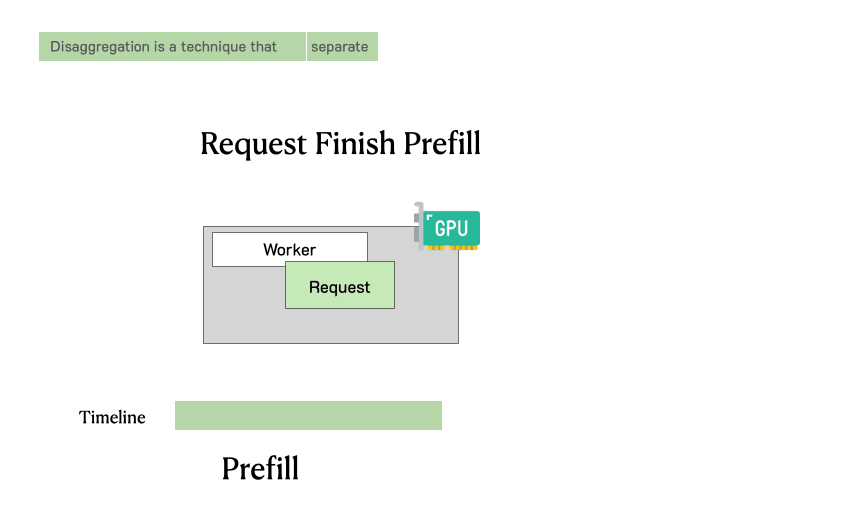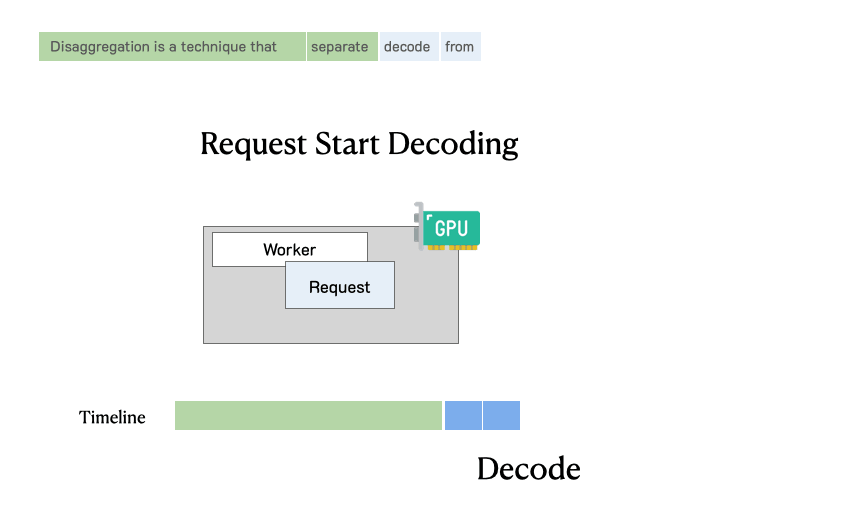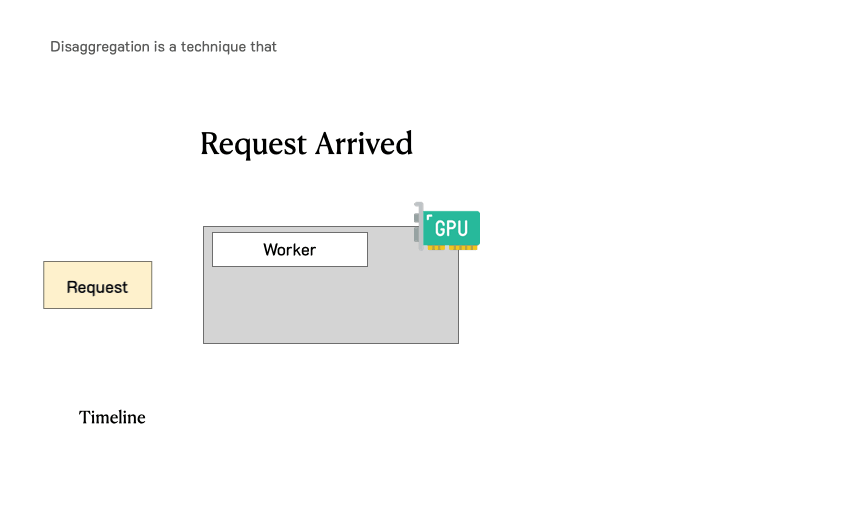
传统LLM服务系统中请求的处理过程
LLM服务系统通常将预填充和解码一起批处理,使用迭代调度或连续批处理技术,使GPU能尽量大批量处理,从而提高吞吐量(每秒token数),vLLM和TensorRT-LLM等系统都广泛采用这一方法。
然而,预填充和解码在计算上有非常不同的特点。
预填充非常依赖计算,意味着即使是一个小批量的预填充,或者仅仅是一个足够长的预填充,也会迅速饱和GPU计算资源。
另一方面,解码需要更大的批量来达到计算瓶颈,且更容易受到GPU内存带宽限制的影响。
不过,预填充和解码在计算上差异很大:预填充计算密集型,容易迅速饱和GPU;而解码则需要更大批量才能达到计算瓶颈,同时也更受GPU内存带宽的限制。
由于它们的计算模式和SLO目标差异巨大,将这两者一起处理并不有利于优化有效吞吐量,原因有二:
预填充和解码之间会互相干扰,导致性能下降
预填充和解码的资源分配及并行策略会相互耦合,难以优化
预填充和解码的干扰
下图展示了预填充和解码之间的干扰。
左:把两个请求批量到一个GPU,结果看到解码(R1)延迟显著增加,预填充(R2)延迟稍微上升。
右:稳定请求流中,每次解码遇到预填充请求时就会被「卡住」,解码延迟因此意外增加。

连续批处理导致的干扰
这种干扰导致下图中展示的情况:为了满足TTFT和TPOT的SLO,系统必须过度配置资源以满足延迟目标,尤其当某个SLO特别严格时。
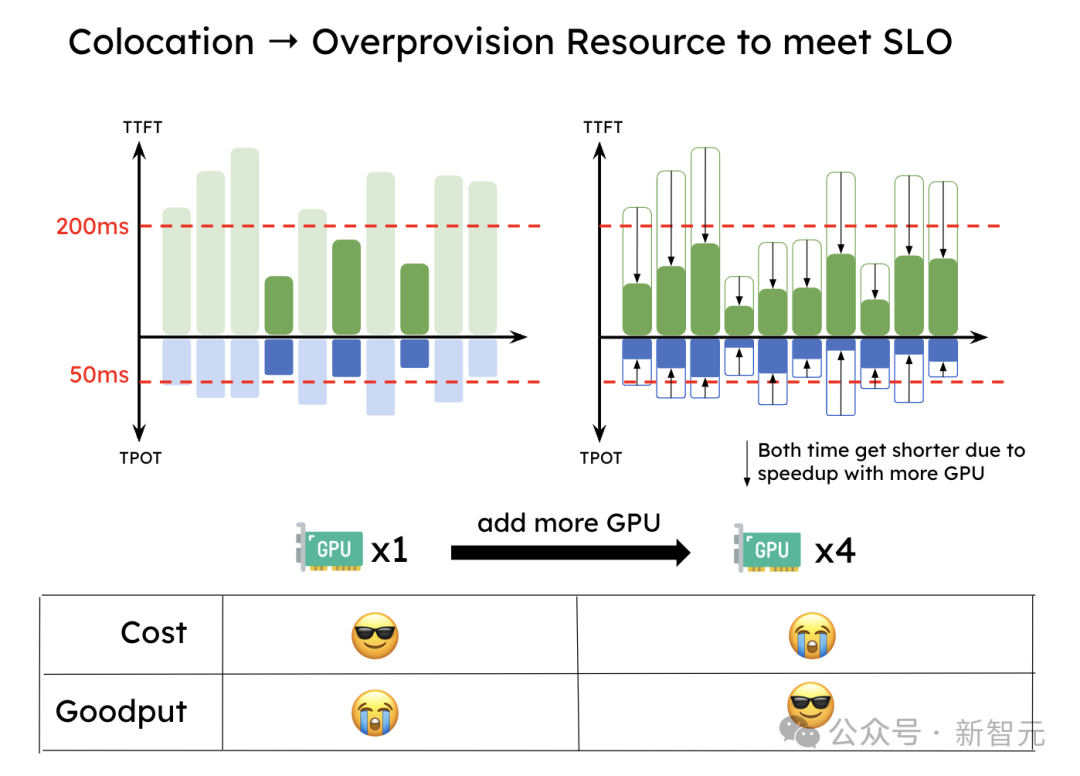
为了满足SLO,预填充和解码共同处理的系统需要过度配置资源
此外,预填充和解码的资源分配和并行策略是耦合的。由于计算模式和延迟目标不同,最优的并行策略也不一样。
比如,当TTFT要求严格时,预填充阶段适合用张量并行(TP)来满足紧凑的延迟目标,而解码则更倾向于数据并行或流水线并行来提升吞吐量。
分离预填充和解码
直觉很简单:将预填充(Prefill)和解码(Decode)分配到不同的GPU,并为每个阶段定制并行策略。
这自然解决了上面提到的两个问题:
预填充和解码之间没有干扰,使得两个阶段都可以更快完成,并更容易满足各自的SLO(服务水平目标)
资源分配和并行策略解耦,优化可以针对预填充和解码分别进行
下图展示了在这种分离系统中请求的处理方式。
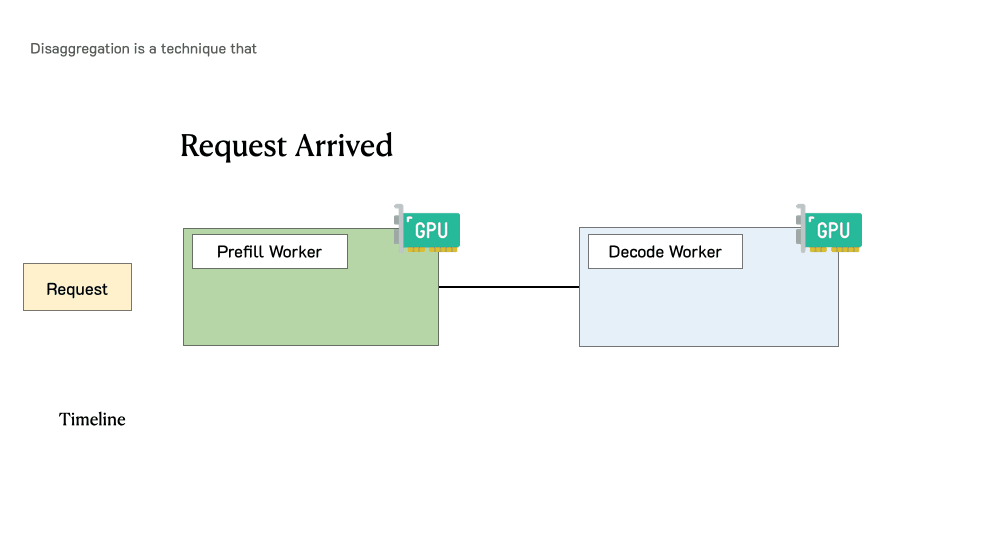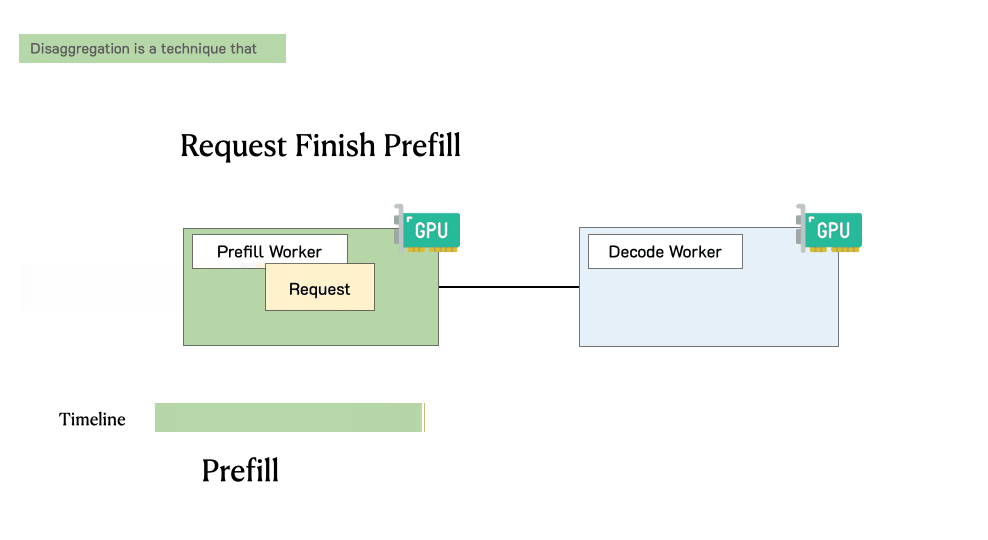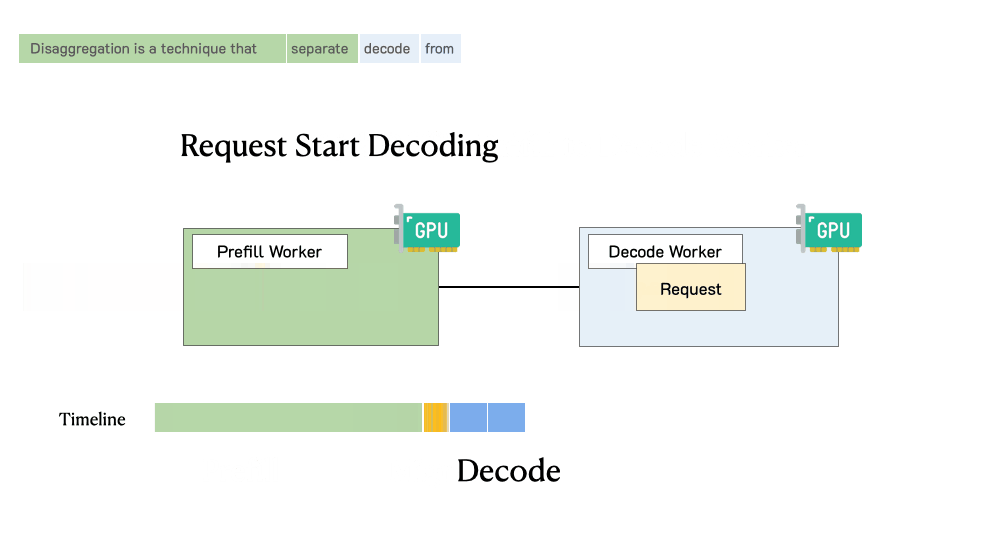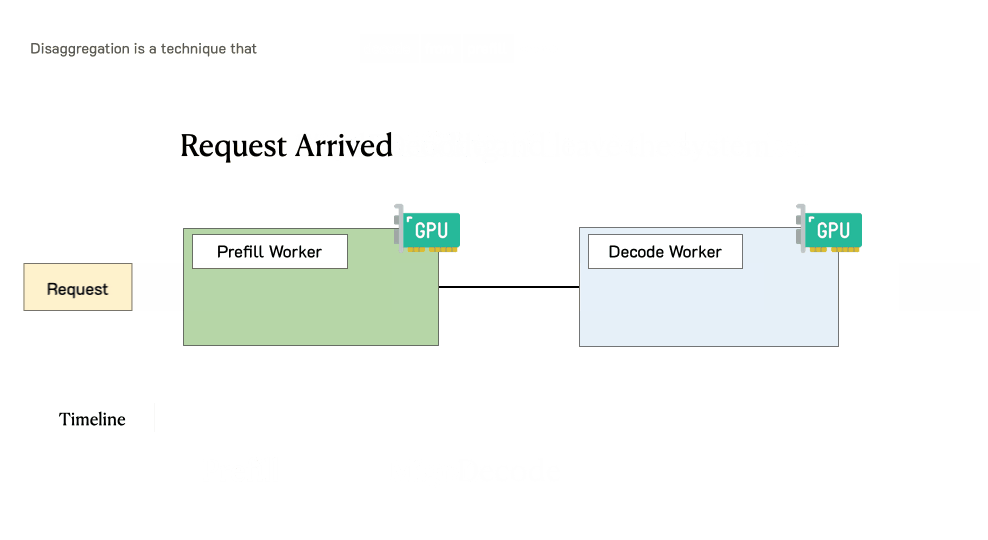
预填充/解码分离时请求的处理过程
当请求到达系统时:
首先进入预填充工作节点并完成预填充阶段
然后,系统将其中间状态(主要是KV缓存)迁移到解码工作节点,并进行多个解码步骤以生成后续token
请求在生成完成后离开系统
通过一个简单的实验,即可验证Prefill-Decode分离的效果。
在单个A100-80GB GPU上运行一个13B的LLM,使用一个输入长度为512、输出长度为64的合成工作负载,并假设请求按泊松分布到达。
逐渐增加请求速率(x轴),并测量这两种延迟(P90 TTFT和P90 TPOT,y轴)中的变化。
假设将SLO设置为P90 TTFT小于0.4秒,P90 TPOT小于0.04秒,作者观察到,现有系统使用1个GPU时,大约支持3个rps(Request rate per second),而TPOT则支持1.6个rps。
由于需要同时满足这两个约束,现有共同处理系统的有效吞吐量为:有效吞吐量(同时满足) = min(3, 1.6) = 1.6 rps(每个GPU)。
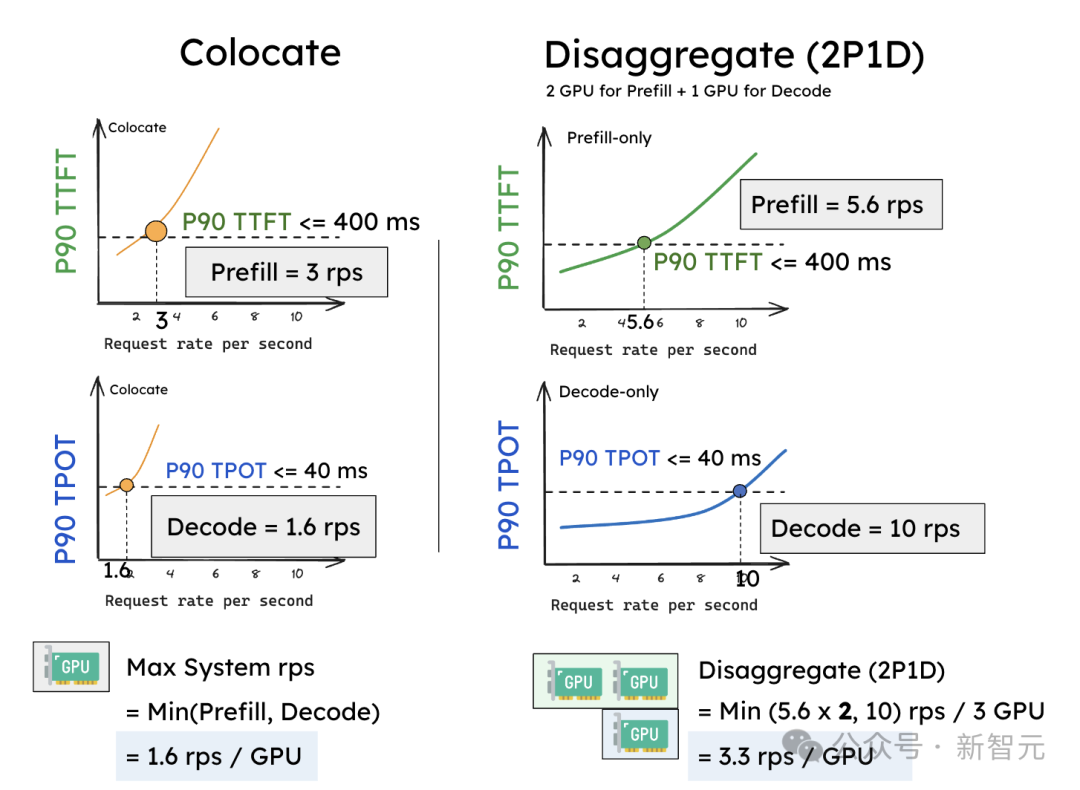
共同处理(a)相较于分离(b),后者在为预填充分配2个GPU、为解码分配1个GPU(2P1D)时更具灵活性
分离后,性能显著提升。
预填充工作节点和解码工作节点在仅处理单个阶段时,可以分别达到比之前更好的rps——预填充工作节点大约可以达到5.6 rps,解码工作节点大约可以达到10 rps。
更重要的是,现在我们可以灵活地分配2个预填充工作节点与1个解码工作节点(记作2P1D),总共使用3个GPU。此时的有效吞吐量变为:
有效吞吐量(2P1D) = min(5.6 x 2, 10) = 10 reqs/s / 3 GPUs ≈ 3.3 reqs/s(平均每个GPU)。
这个实验表明,简单的分离方法在没有任何并行化的情况下就能实现2倍的有效吞吐量(3.3rps VS 1.6rps)。
额外的好处是,预填充与解码的分离还能够为每个阶段选择最佳的并行策略来优化有效吞吐量(作者称之为「定制并行tailored parallelism」)。
KV缓存传输
分离的一个代价是需要在预填充和解码GPU之间传输中间状态(即KV缓存)。
乍一看,KV缓存是LLM推理中一个大的内存开销,而在GPU之间传输KV缓存似乎是一个瓶颈。
但相反,通过合理的放置,KV缓存传输的开销可以被有效地最小化,低至小于一个解码步骤的时间,这得益于今天高速的网络技术,如NVLink和PCI-e 5.0。
为了验证这一点,假设有8通道PCIe 5.0 x 16(每个链路64GB/s)作为GPU之间的节点内网络。
给定一个2048token的请求,可以估算在服务OPT-175B(OPT,即Open Pre-trained Transformer由Meta AI开发)时,传输KV缓存的延迟为:
延迟 = 2048token *(4.5 MB/token)/(64GB/s * 8) = 17.6毫秒
这个延迟小于OPT-175B的单个解码步骤的时间(约30-50毫秒,使用A100)。
对于更大的模型、更长的序列或更先进的网络(例如,具有600GB/s带宽的A100-NVLink),如下图所示,KV缓存传输的比较开销与单个解码步骤相比变得更加微不足道。
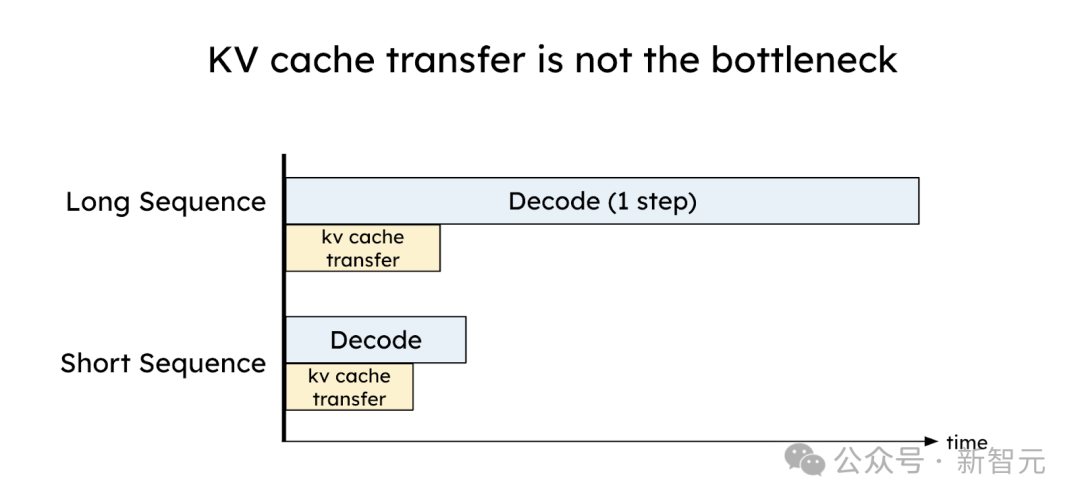
KV缓存传输开销可以被有效最小化,低于一个解码步骤的时间
精心放置预填充和解码工作节点以利用高带宽网络,可以有效地隐藏KV缓存传输的开销。
DistServe:评估分离的效果
作者在一个名为DistServe的系统原型中实现了所提出的技术,并在三个具有不同延迟约束的工作负载和数据集上与现有系统进行了比较:聊天机器人、代码补全和摘要,详细信息见下表。

下图展示了DistServe与vLLM的对比结果:

在各种数据集上评估DistServe与vLLM的表现
聊天机器人:DistServe的有效吞吐量比vLLM高2.0倍到3.41倍。
代码补全:DistServe的有效吞吐量比vLLM高3.2倍,并且SLO比vLLM严格1.5倍。作为实时编码助手,代码补全任务比聊天机器人要求更低的TTFT,这使得两个系统最终都受到TTFT要求的限制。然而,通过消除解码任务的干扰,并为预填充定制张量并行策略,DistServe减少了预填充任务的平均延迟,从而满足更多请求的TTFT要求。
摘要:DistServe的有效吞吐量比vLLM高4.48倍,并且SLO比vLLM严格10.2倍。如预期的那样,由于vLLM将预填充和解码放在一起,它在解码阶段的减速更大,未能满足TPOT要求。
团队成员介绍
以上研究出自加州大学圣地亚哥分校的Hao AI实验室,全部来自于华人研究者。

Junda Chen

2023年秋季入学的计算机科学博士生。研究兴趣:高效的LLM服务系统、推理系统和算法。
Yinmin Zhong

北京大学计算机系统研究组的一名三年级博士生,导师是金鑫。在此之前,在北京大学获得了计算机科学学士学位。对构建高效的系统来训练和提供深度学习模型有广泛的兴趣,目前主要关注大语言模型。
Hao Zhang

加州大学圣地亚哥分校计算机科学与工程系的助理教授。在UCSD领导Hao AI实验室,对设计强大、高效和安全的机器学习模型和算法,以及构建可扩展、实用的分布式系统以支持现实世界的机器学习工作负载感兴趣。
文章来源于互联网:凤凰网-揭秘老黄演讲中关键技术:PD分离!UCSD华人团队力作,LLM吞吐量跃升4倍
相关推荐
-
英伟达NVIDIA GeForce RTX 4070 SUPER正式发布 起价599美元
今日,英伟达NVIDIA正式发布了新品显卡——GeForce RTX 4070 SUPER。这款显卡配备了Ada Lovelace AD104 GPU,起价为599美元,旨在为14…
-
三星Samsung Galaxy Tab Active5平板高清渲染图曝光:强大性能与坚固耐用并存
近日,国外科技媒体 mspoweruser 分享了三星Samsung Galaxy Tab Active5 平板的高清渲染图,这款平板电脑以其强大的性能和坚固耐用的特性引起了广泛关…
-
英伟达确认RTX 5070公版显卡推迟到“3月下旬”上市,大批非公版今晚上市
IT之家 3 月 5 日消息,英伟达 GeForce RTX 5070 显卡已于昨晚解禁,并将于今晚 22:00 正式上市(但截至发稿仍未公布国行指导价),但现在看来首发阶段只有非…
-
2024年1月中国电视市场出货量达419万台,小米位列第一
IT之家 2 月 19 日消息,根据洛图科技(RUNTO)发布的数据显示,2024 年 1 月,中国电视市场品牌整机出货量达到 419 万台,同比增长 24.3%,环比增长 21….
-
ANTSHARE三星Galaxy S24手机壳在美国亚马逊可以省6美元,仅售13.59美元!
ANTSHARE三星Galaxy S24手机壳是一款高品质、功能齐全的保护配件,其折扣非常大,目前美国亚马逊正在开展一项优惠活动,您可以以13.59美元的价格购买该产品,可以享受6…
-
Cosmic Byte ARES PC无线控制器在印度亚马逊可以省309卢比,仅售1890卢比!
Cosmic Byte ARES PC无线控制器是一款专为游戏而生的神器,其折扣非常大,目前印度亚马逊正在开展一项优惠活动,您可以以1890卢比的价格购买该产品,可以享受309卢比…
-
第一个iPhone刺客,倒下了
旗舰产品推出才一个月,创始人就想卖掉公司。 败局来得太快。 推出 AI Pin 仅一个月后,Humane 试图为其业务寻找下家。就在上周, AI Pin 还接入了 GPT-4o,改…
-
稀疏算力暴涨591%!Meta推出5nm AI训练芯片,自研AI芯片盛世来了
作者 | ZeR0 编辑 | 漠影 智东西4月11日报道,美国AI三巨头不仅在大模型赛道争奇斗艳,还纷纷卷起自研AI芯片。昨天“AI界汪峰”谷歌刚推出新款云端定制芯片,今天Meta…
-
新STEALTH系列背插款式在路上:技嘉备案注册大量主板新品
IT之家 2 月 18 日消息,X 平台消息人士 포시포시 (@harukaze5719) 注意到,技嘉本月早些时候向 EEC 欧亚经济委员会备案注册了大量主板新品,其中就包含两款…
-
比苹果Vision Pro便宜:三星XR头显被曝2000~3000美元价位
IT之家 1 月 30 日消息,消息源 @PandaFlashPro 于 1 月 28 日在 X 平台发布推文,曝料三星的 XR 头显售价高于 2000 美元但低于 3000 美元…
