
Enfabrica Corp.,一家备受瞩目的初创公司,正在AI领域掀起波澜。去年9月,该公司在B轮融资中筹集了1.25亿美元,并吸引了AI巨头英伟达的投资,这算是英伟达的一个竞争对手,因为这家初创公司研发的AI网络芯片被业界认为有望对英伟达旗下的Mellanox解决方案构成挑战。而就在本月,Enfabrica再次完成C轮融资,获得了包括Arm、思科、三星等巨头的1.15亿美元的资金支持。那么,是什么让Enfabrica脱颖而出,吸引了如此多行业巨头的持续青睐?
Enfabrica是谁?
Enfabrica这家初创公司成立于2020年,由 Sutter Hill Ventures 资助,由首席执行官Rochan Sankar、首席开发官 Shrijeet Mukherjee以及其他工程师创立。该公司创立之初的基本理念是数据中心的网络结构必须改变,因为底层计算范式正在发生变化:更加并行、加速、异构和数据移动密集。

图源:Enfabrica
直到 2023 年 3 月,该公司才开始被行业知晓。Enfabrica也被The information评为是2024年最有前途的50家初创公司。
不过成立仅4年,该公司却获得了一众资本的认可:
2023年9月,Enfabrica宣布融资1.25亿美元,B 轮融资由 Atreides Management 领投,现有投资者 Sutter Hill Ventures 参投,新支持者包括 IAG Capital Partners、Liberty Global Ventures、Nvidia Corp.、Valor Equity Partners 和 Alumni Ventures。
2024年11月19日,该公司宣布筹集了1.15亿美元可观的新现金注入,其C轮融资由 Spark Capital 领投,加入此轮融资的新投资者包括 Arm、Cisco Investments、Maverick Silicon、Samsung Catalyst Fund 和 VentureTech Alliance。去年参与 B 轮融资的现有投资者 Atreides Management、Sutter Hill Ventures、Alumni Ventures、IAG Capital 和 Liberty Global Ventures 也参与了此次融资。
随着OpenAI的ChatGPT等大语言模型的兴起,对生成式AI应用以及现在的AI代理产生了巨大的需求,这家初创公司适时推出了其AI网络互连芯片——ACF-S(Accelerated Compute Fabric-Switch,加速计算结构交换机)。ACF解决方案是从头开始发明和开发的,旨在解决GPU网络痛点以及内存和存储扩展问题等加速计算的扩展挑战。包括英伟达在内的知名投资机构对Enfabrica的大力支持,进一步证明了其技术的商业可行性和潜在价值。
网络连接,需要改变了
在现代AI服务器和数据中心中,存在多种连接技术,可能很多人会有所迷糊,在此作简单科普。通常我们所说的PCIe、英伟达的NVLink、AMD的Fabric这些主要是用于服务器与服务器之间的纵向连接。而网络技术则是指用于多个服务器横向连接,例如AI训练集群中的多节点通信。
AI训练过程由频繁的计算和通信阶段交替组成,其中下一阶段的计算需要等待通信阶段在所有GPU之间完成后才能启动。通信阶段的尾部延迟(tail latency,即最后一条消息到达的时间)成为整个系统性能的关键指标,因为它决定了所有GPU是否能同步进入下一阶段。在这一过程中,网络的重要性愈发凸显,网络通信需要能够传输更多的数据。若网络性能不足,这些高成本的计算集群将无法被充分利用。而且,连接这些计算资源的网络必须具备极高的效率和成本效益。
在高性能计算(HPC)网络中,Infiniband、OmniPath、Slingshot是几个横向连接技术方案。
其中Infiniband主要由NVIDIA(通过其Mellanox子公司)主导,是HPC领域最成熟的网络技术之一。它以极低的延迟和高带宽著称,支持远程直接内存访问(RDMA),广泛应用于超级计算和AI训练。该技术成本较高,部署和维护复杂性较高。目前,Nvidia 是 InfiniBand 芯片的最大卖家。例如,英伟达的ConnectX-8 InfiniBand SuperNIC支持高达800Gb/s的InfiniBand和以太网网络连接,能够运行数十万台GPU。

英伟达的ConnectX-8 InfiniBand SuperNIC
(图源:英伟达)
OmniPath是由英特尔推出的一种高性能网络技术,旨在与Infiniband竞争,虽然英特尔于2019年停止直接开发,但Cornelis Networks接管了该技术,继续发展。相比Infiniband,OmniPath的硬件和部署成本更低,适合中型HPC集群。但OmniPath的市场份额有限,生态系统不如Infiniband成熟,技术更新速度较慢。
Slingshot是由Hewlett Packard Enterprise(HPE)旗下的Cray开发的高性能网络技术。其特色在于与以太网的兼容性,适合混合HPC和企业工作负载的场景。不过,Slingshot尚未在市场中被大规模应用,市场接受度和应用案例还有待观察。
不过与HPC网络相比较,AI对网络需求提出了更高的要求,已从最初的高性能计算要求转向构建可在加速计算集群之间提供一致、可靠、高带宽通信的系统,这些集群现在有 10,000 个节点或更大,并且需要以类似云的服务的形式提供。
为了打破InfiniBand的垄断,以太网正逐渐成为有力竞争者。以太网虽起源于通用网络技术,但其广泛的生态系统、低成本和逐步增强的性能,使其在HPC和AI横向连接技术中崭露头角。以太网的优势在于生态成熟和成本效益,但在延迟和专用功能上仍需努力。因而去年,超级以太网联盟(UEC)成立,该联盟的宗旨是“新的时代需要新的网络”,UEC对新网络的定义是:性能堪比超级计算互连、像以太网一样无处不在且经济高效、与云数据中心一样可扩展。UEC的创始成员包括AMD、Arista Networks、Broadcom、思科系统、Atos 的 Eviden 分拆公司、惠普企业、英特尔、Meta Platforms 和微软。值得一提的是,后来英伟达也加入了这一联盟。

来源:超级以太网联盟(UEC)
所有这些网络技术往往依赖于专用的网络接口卡(NIC)和交换机。当前,AI服务器的网络组件如NICs、PCIe交换机和Rail Switches,大都像“烟囱式”(stovepipes)结构一样单独存在(如下图所示),彼此之间缺乏统一协调,网络带宽不足,缺乏可靠的容错机制,难以应对AI训练和推理过程中庞大的数据流量。

图源:Enfabrica
这样的结构特点还带来了诸多痛点:如在GPU之间传输数据时容易产生拥堵,数据在网络中需要经过多个设备跳转,增加了延迟;网络负载分布不均,可能导致“入汇拥塞”(incast),即大量数据同时到达某一点时引发的瓶颈;此外,碎片化和低效率的网络设计导致AI集群的总成本(TCO)显著增加,因为存在GPU和计算资源闲置的情况,造成资源浪费与带宽利用率低,GPU间的链路如果发生故障,会导致整个任务停滞,影响系统的可靠性和稳定性。
行业变革日新月异,现在GPU已经取代CPU成为AI数据中心的核心处理资源,GPU和加速器计算基础设施的资本支出在全球所有顶级云提供商中占据传统计算支出的主导地位——这一切都归功于生成式 AI 的市场潜力。但值得注意的是,目前部署在这些系统中的网络芯片,包括连接加速计算的PCIe交换机、NIC网络接口控制器和机架顶交换机,依然是为传统x86计算架构时代设计的产品。这些设备上 I/O 带宽的滞后已经成为AI扩展的瓶颈。
网络芯片,也需要与时俱进了。本文我们所描述的Enfabrica公司,他们开发的ACF-S技术有望在这一领域占据一席之地。
取代多种网络芯片,
ACF-S芯片要“革互连的命”
Enfabrica的ACF-S是一种服务器结构芯片,它不使用行业标准的PCIe交换机和具有RDMA 的以太网网络接口卡 (NIC),而是将CXL/PCIe交换功能和RNIC(远程网络接口卡)功能集成到单一设备中,也就是不再需要PCIe、NIC(网络接口控制器)或独立的CPU连接DRAM,而且这种方法消除了对CXL高级功能的依赖。这种架构和思路与超级以太网(UEC)白皮书所倡导的所有方面都需要加速器、NIC 和交换机结构之间的协调不谋而合。

图源:Enfabrica
Enfabrica 首席执行官 Rochan Sankar表示:“这不是CXL架构,不是以太网交换机,也不是DPU——它可以做所有这些事情。这是一类不同的产品,可以解决不同类别的问题。”
据了解,Enfabrica的ACF-S采用100%基于标准的硬件和软件接口,包括原生多端口800千兆以太网网络和高基数PCIe Gen5和CXL 2.0+接口。该结构可直接桥接和互连GPU、CPU、加速器、内存和网络等各种设备,在这些设备之间提供可扩展、流式、每秒多TB的数据传输。它将消除对专用网络互连和传统机架顶部通信硬件的需求,充当通用数据移动器,克服现有数据中心的I/O限制。
也就是说,ACF-S无需改变设备驱动程序之上的物理接口、协议或软件层,即可在单个硅片中实现异构计算和内存资源之间的多TB交换和桥接,同时大幅减少当今 AI 集群中由机架顶部网络交换机、RDMA-over-Ethernet NIC、Infiniband HCA、PCIe/CXL交换机和连接 CPU的DRAM所消耗的设备数量、I/O 延迟跳跃和设备功率。
通过结合独特的CXL内存桥接功能,Enfabrica的ACF-S成为业内首款可为任何加速器提供无头内存扩展的数据中心硅产品,使单个GPU机架能够直接、低延迟、无争用地访问本地CXL DDR5 DRAM,其内存容量是GPU原生高带宽内存 (HBM) 的50倍以上。
成本也是这家初创公司的卖点之一。这是由于节省了购买NIC和PCIe交换机的费用。据该公司称,Enfabrica的旗舰ACF交换机硅片使客户能够在相同性能点上将大型语言模型 (LLM) 推理的GPU计算成本降低约50%,将深度学习推荐模型 (DLRM) 推理的GPU计算成本降低75%。
3.2Tbps超高速,实现50多万GPU互连
2024年11月19日,在超级计算 2024 (SC24) 大会上,Enfabrica宣布其突破性的3.2太比特/秒 (Tbps) ACF SuperNIC芯片“Millennium”及其相应的试点系统 Thames全面上市。Millennium为 GPU 服务器提供多端口 800 千兆以太网连接,带宽和多路径弹性是业内任何其他 GPU连接网络接口控制器 (NIC) 产品的四倍。Enfabrica芯片将于2025年第一季度开始批量供货。

图源:Enfabrica
Millennium具有高基数、高带宽和并发 PCIe/以太网多路径和数据移动功能,可以独特地在每个服务器系统中纵向和横向扩展四到八个最新一代 GPU,为 AI 集群带来前所未有的性能、规模和弹性。Millennium 还引入了软件定义的 RDMA 网络,将传输堆栈控制权交给数据中心运营商,而不是 NIC 供应商的固件,而不会影响线速网络性能。
凭借单个ACF-S芯片上的800、400和100千兆以太网接口以及32个网络端口和160个PCIe通道的高基数,首次可以使用更高效的两层网络设计构建超过50万个GPU的AI集群,从而实现集群中所有GPU的最高横向扩展吞吐量和最低的端到端延迟。
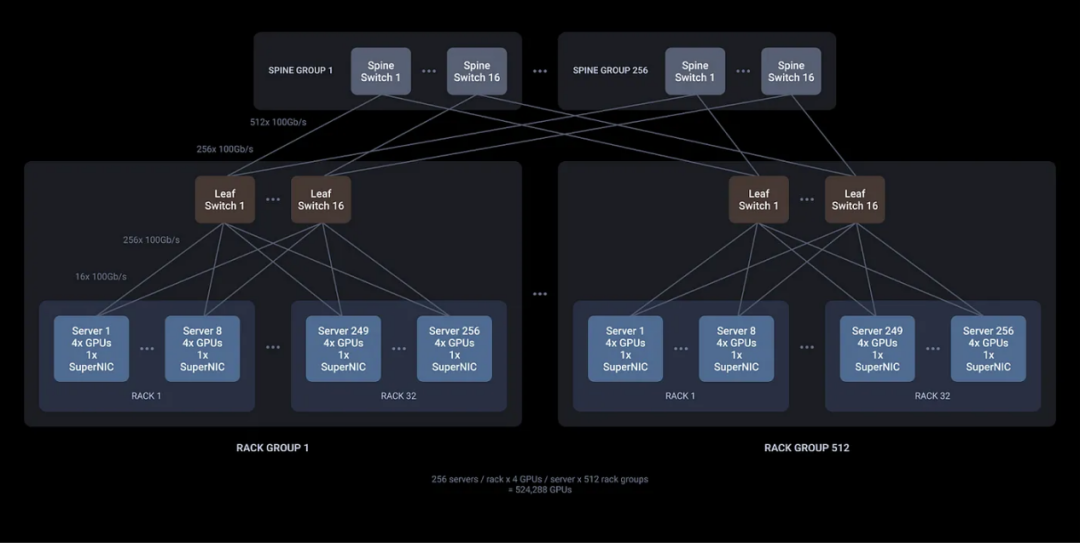
2层500K+ GPU集群设计(跨所有网络层的完整横截面带宽)(图源:Enfabrica)
Enfabrica相信其互联技术将成为未来GPU计算网络的核心。Constellation Research Inc. 副总裁兼首席分析师Andy Thurai表示,Enfabrica可以为AI网络领域提供一个有趣的替代方案,目前该领域由 Nvidia 及其 Mellanox 解决方案主导。他解释说,Enfabrica 的一个显着差异是它能够在GPU和CPU之间高速移动数据。
也就说,不仅是GPU,Enfabrica还有望改变CPU的竞争力。Thurai 表示:“这可以让更多公司探索使用CPU而不是GPU来开发人工智能,因为GPU目前供应不足。Enfabrica的独特优势在于它使用现有的接口、协议和软件堆栈,因此无需重新连接基础设施。”
结语
随着AI模型训练对效率和成本效益的要求不断提高,网络的重要性愈发凸显。据650 Group预测,到2027年,数据中心在计算、存储和网络芯片高性能I/O领域的硅片支出将翻倍,超过200亿美元。这无疑是一块极具吸引力的市场蛋糕。
英伟达等公司对Enfabrica初创公司的投资,不仅彰显了对其技术创新的高度认可,更是着眼于未来AI生态战略布局的一步棋。要突破当前人工智能领域面临的网络I/O瓶颈,离不开应用人工智能、GPU计算和高性能网络领域的专家之间的创造性工程设计和紧密协作。只有摒弃孤立竞争,形成合力,才能共同推动技术进步,为行业注入新动力。
END
文章来源于互联网:凤凰网-英伟达投资了一家芯片“竞争对手”
相关推荐
-
三星Galaxy Ring新功能泄露:心率、压力、体温与打鼾检测一应俱全
近日,外媒Android Authority通过对三星健康App的深入分析,提前曝光了即将于7月10日正式发布的三星Galaxy Ring功能信息。这款备受期待的智能戒指在健康监测…
-
美光发布全球最大、最快61.44TB SSD!232层TLC闪存
快科技11月13日消息,美光发布了新一代旗舰企业级SSD 6500 ION,号称世界上容量最大、速度最快、能效最高的SSD:支持PCIe 5.0,最高60TB,采用TLC而非QLC…
-
三星承认软件更新导致大量回音壁变砖,承诺将免费维修受影响设备
IT之家 3 月 23 日消息,三星今日向外媒 The Verge 证实,由于“软件更新错误”,部分 2024 款回音壁设备无法正常使用。三星电子美国公司音频部门主管 Jim Ki…
-
PTron Bassbuds Tango ENC在印度亚马逊可以省3200卢布,仅售799卢布!
PTron Bassbuds Tango ENC是一款令人惊艳的蓝牙真正无线入耳式耳机,其折扣非常大,目前印度亚马逊正在开展一项优惠活动,您可以以799卢布的价格购买该产品,可以享…
-
OpenAI首颗自研芯片曝光!苹果也已下单
OpenAI 首款内部 AI 芯片再次传来新的消息。 据台湾经济日报报道,台积电将开发一款专为 OpenAI Sora 视频模型定制的 A16 埃米级工艺芯片,旨在提升 Sora …
-
赛昉科技发布全新RISC-V处理器内核“昉・天枢-83”,性能超越Arm A75
IT之家 12 月 10 日消息,RISC-V 软硬件生态企业赛昉科技今日宣布推出全新 RISC-V 处理器内核 —— 昉・天枢-83(Dubhe-83),用于 AI 应用与高效计…
-
华为Sound Joy 2蓝牙智能音箱通过认证:支持40W快充,有望7月上市
IT之家 6 月 29 日消息,华为 Sound Joy 2 蓝牙智能音箱近日通过国内质量认证,型号为 EGRT-00、EGRT-09,支持最大 40W 快充。认证信息显示,华为 …
-
央视315晚会曝光制造水军的主板机 涉及多款手机
【CNMO科技消息】3月15日,央视315晚会曝光主板机黑灰产业链,网络水军利用主板机随意更改IP逃避监管。 “20块手机主板就能集成一个主板机了,一台电脑可以投屏上百台手机,可以…
-
库存充足:消息称苹果现款Vision Pro已大幅减产,可能会在2024年底彻底停产
IT之家 10 月 23 日消息,The Information 报道称,苹果已大幅削减 Vision Pro 头显的产量,并可能在 2024 年底前完全停止生产这一版本的设备。 …
-
苹果官方没宣传:M4 MacBook Pro首发量子点显示技术
快科技11月16日消息,显示专家Ross Young在社交平台上表示,最新的M4 MacBook Pro使用量子点(QD)薄膜,而不是红色KSF荧光粉薄膜。 过去苹果通常采用KSF…
