



在当今的大模型竞赛中,GPT-4 Turbo依然表现出色,通过全面评测,OpenCompass2.0大语言模型中英双语客观评测前十名显示,智谱清言GLM-4、阿里巴巴Qwen-Max和百度文心一言4.0等中国国内模型在某些方面已经与GPT-4 Turbo相当。
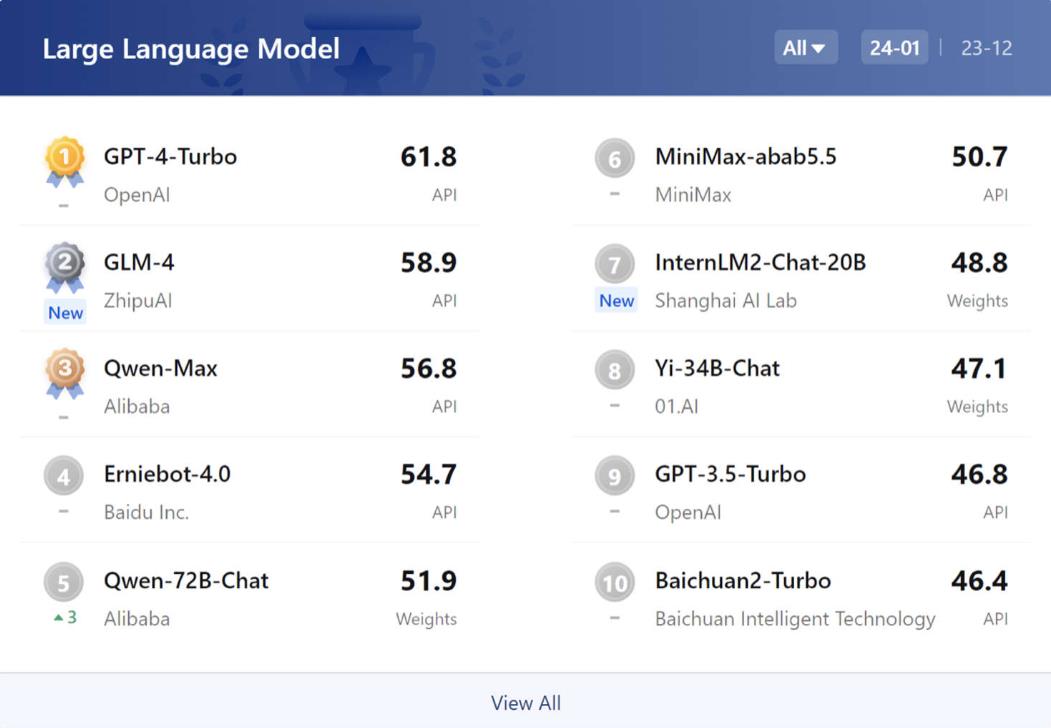
然而,大模型的真正实力并不仅仅取决于跑分和刷榜。全方面的能力,包括推理、数学、代码和智能体等方面的表现,都是衡量一个大模型是否优秀的关键因素。在这方面,GPT-4 Turbo的表现依然领先,但国内模型也在不断进步。
为了更全面地评估大模型的真实水平,OpenCompass2.0构建了一套中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话等方面。通过这种方式,我们能够更准确地量化模型在知识、语言、理解、推理和考试等五大能力维度的表现。
在中文主观评测中,国内商用大模型表现出色,与GPT-4 Turbo的差距进一步缩小。这表明在国内场景下,国内最新大模型已展现出优势。在数学等高难度推理任务上,GPT-4 Turbo仍具有领先优势,而国内模型在中文语言理解、知识和创作上具有更强的竞争力。
总的来说,虽然GPT-4 Turbo在大模型领域依然保持领先地位,但国内模型正在迅速发展,不断缩小与国际顶尖模型的差距。通过不断的技术创新和优化,我们有理由相信,国内模型在未来将迎来更大的突破和进步。
文章来源于互联,不代表科技云立场!如有侵权,请联系我们。
相关推荐
-
2023年全球智能手机市场:苹果Apple取代三星Samsung成为领头羊,竞争格局重塑
在2023年,全球智能手机市场格局发生了重大变化。据市场研究公司IDC的数据显示,苹果成功超越三星,成为全球最大的智能手机品牌。这一转变标志着手机市场进入了一个新的时代,未来的竞争…
-
警惕!谷歌Play商店发现恶意软件:VajraSpy威胁安卓用户
近日,ESET网络安全研究人员发出警告,称在谷歌Play商店中发现了6个带有VajraSpy恶意软件的应用程序。这些应用程序能够窃取用户的个人身份信息,包括联系人、文件、通话记录和…
-
谷歌Google Chrome更新:实时字幕功能新增支持11种语言,包括中文和日语
近日,谷歌针对其Google Chrome浏览器发布了Canary频道的测试更新,其中最引人注目的功能更新是实时字幕功能新增了11种语言支持,其中包括简体中文和日语。这次Googl…
-
马斯克:特斯拉Tesla五年内市值有望超越苹果Apple和沙特阿美
近日,特斯拉Tesla首席执行官埃隆·马斯克再次重申了他对特斯拉的雄心壮志,声称该公司五年内有可能超越苹果和沙特阿美石油公司的市值总和。这一预测虽然大胆,但并非没有依据。 马斯克在…
-
苹果Apple Vision Pro首发可用流媒体应用 Netflix不在其中
苹果公司Apple于本周早些时候发布了Vision Pro,一款具备多项创新功能的头显设备。然而,据最新消息,流媒体服务巨头Netflix并未为这款设备开发原生应用,用户无法在Ap…
-
iPad Air将发布12.9英寸版 供应链开始为苹果提供面板
苹果公司一直以其出色的产品设计和卓越的用户体验赢得了全球消费者的喜爱。最近,有消息透露,苹果计划在明年3月份发布一款新的iPad Air,这款平板电脑的屏幕尺寸将达到12.9英寸,…
-
openEuler Summit 2023:汇聚全球智慧,共筑开源新梦
[中国,北京,2023年12月16日]openEuler Summit 2023在北京国家会议中心圆满落幕。本次峰会由openEuler社区成员单位麒麟软件、麒麟信安、华为公司、超…
-
三星Samsung CEO李在镕无罪释放后,韩国检察官提出上诉
2月8日,韩国首尔,一场关于商业巨头三星Samsung电子的诉讼风暴正在酝酿。据韩媒报道,韩国检察官对首尔中央地方法院的一审判决提出上诉,要求重新审理三星电子会长李在镕在2015年…
-
传闻苹果或摒弃传统发布会 以线上形式推出2024款iPad与Mac新品
彭博社知名记者马克・古尔曼 (Mark Gurman) 近日透露,苹果公司将不再通过传统的线下发布会来展示其新款iPad和Mac电脑。相反,他们计划通过官方网站发布一系列线上视频和…
-
Best Buy推出Envision应用程序:让顾客沉浸式体验产品
在数字化购物日益普及的今天,百思买Best Buy集团宣布推出了一款名为“Envision”的应用程序,该应用程序专为苹果用户设计,致力于提供更加专业的视觉购物体验。Envisio…